什么是分布式
将系统差分成不同的服务然后将这些服务放在不同服务器减轻单台服务的压力,提高性能和并发量。
CAP原则:分布式的三个指标, 这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
Consistency(一致性): 写操作之后的读操作,必须返回该值
Availability(可用性): 意思是只要收到用户的请求,服务器就必须给出回应
Partition tolerance(分区容错): 大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。
CA为什么不能同时成立?因为可能通信失败(分区容错)
Base理论:BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)的简写
软状态:指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统事务的ACID特性使相反的,它完全不同于ACID的强一致性模型,而是提出通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性与BASE理论往往又会结合在一起使用。
Eureka 典型的 AP,作为分布式场景下的服务发现的产品较为合适,服务发现场景的可用性优先级较高,一致性并不是特别致命。其次 CA 类型的场景 Consul,也能提供较高的可用性,并能 k-v store 服务保证一致性。 而Zookeeper,Etcd则是CP类型 牺牲可用性,在服务发现场景并没太大优势;
| Eureka | Zookeeper | Consul | |
|---|---|---|---|
| GitHub | https://github.com/Netflix/eureka | https://github.com/apache/zookeeper | https://github.com/hashicorp/consul |
| 服务健康度检查 | 服务状态,内存,硬盘等 | (弱)长连接,keepalive | 连接心跳 |
| 多数据中心 | — | 支持 | 支持 |
| k-v存储服务 | — | 支持 | 支持 |
| 一致性 | — | paxos(Paxos算法是保证在分布式系统中写操作能够顺利进行,保证系统中大多数状态是一致的,没有机会看到不一致,因此,Paxos算法的特点是一致性>可用性。) | rafthttp://raft.taillog.cn/ |
| cap | ap | cp | ca |
| 多语言能力 | http(sidecar) | 客户端 | 支持http和dns |
| watch支持 | 支持 long polling/大部分增量 | — | metrics |
| 自身监控 | metrics | — | metrics |
| 安全 | — | acl | acl /https |
| SpringCloud集成 | 已支持 | 已支持 | 已支持 |

synchronized是一种同步锁
同一时刻只能有一个线程能获取到锁

Volatile 能够保证可见性。
volatile的两大特性:禁止重排序、内存可见性。
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,新值对其他线程来说是立即得知的。
2)禁止进行指令重排序。
Optional是Java8提供的为了解决null安全问题的一个API。
阿里巴巴编码规约-异常处理
1 | 说明:本手册明确防止 NPE 是调用者的责任。 |
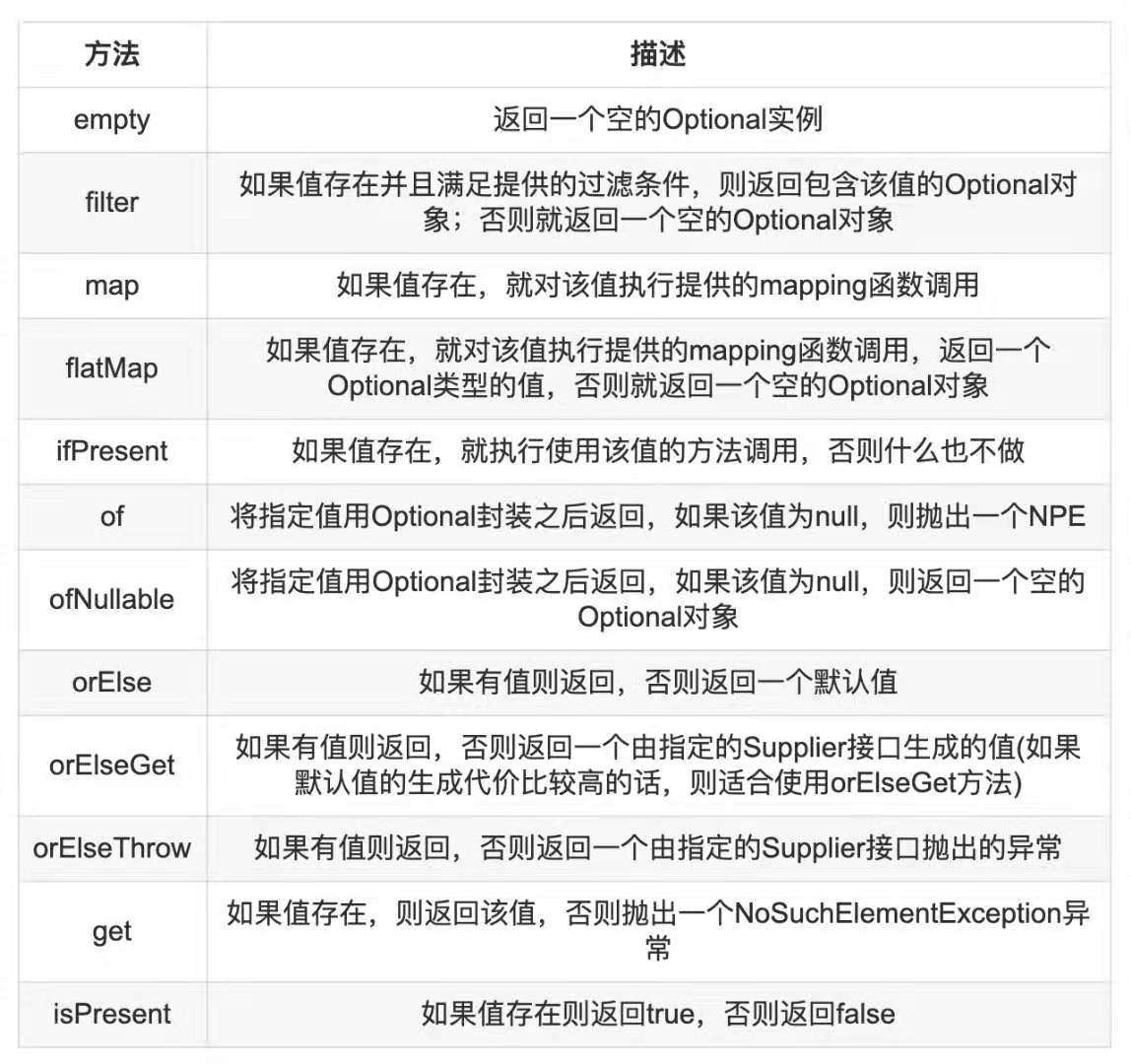
方法:Optional.of、Optional.ofNullable、Optional.empty():
1 | `Optional emptyOptional = Optional.empty(); Optional nonEmptyOptional = Optional.of("name"); Optional nonEmptyOptional = Optional.ofNullable(null); ` |
方法:Optional.isPresent()、Optional.ifPresent()
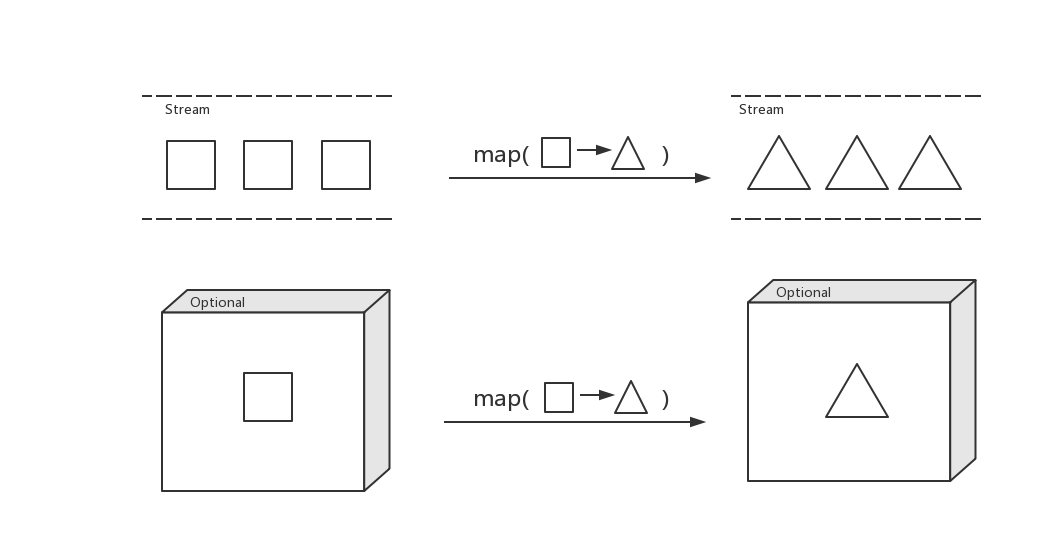

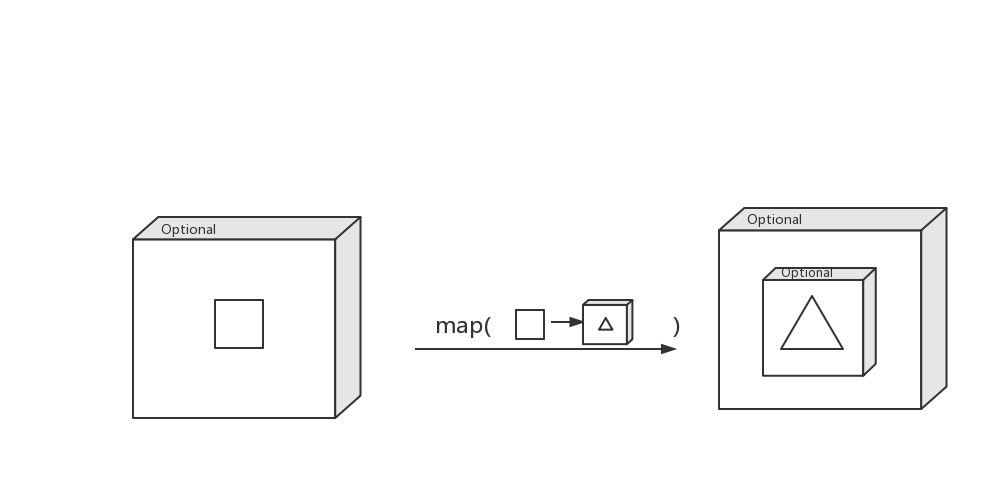
1 | `String name = "Aa"; Optional optionalName = Optional.of(name).filter(str -> str.length() > 2);` |
由于Optional 类设计时就没特别考虑将其作为类的字段使用,所以它也并未实现Serializable;
把 Optional 类型用作属性或是方法参数在 IntelliJ IDEA 中更是强力不推荐的
用Optional 声明域模型中某些类型是不错的主意。
如果非要实现序列化的模型域,可以参考下例
https://docs.oracle.com/javase/8/docs/api/java/lang/doc-files/ValueBased.html
这里说的是基于值的类需要满足以下几点:
1、 final类型和不可变的(可能会包含可变对象的引用)
2、 有equals、hashCode、toString方法的实现,它是通过实例的状态计算出来的,而并不会通过其它的对象或变量去计算。
3、 不会使用身份敏感的操作,比如在二个实例之间引用相等性、hashCode或者内在的锁。
4、 判断二个值相等仅仅通过equal方法,而不会通过==去判断。
5、 它不提供构造方法,它通过工厂方法创建它的实例,这不保证返回实例的一致性。
6、 当它们相等时,它是可以自由替换的。如果x和y 调用equal方法返回true,那么可以将x和y任意交换,它的结果不会产生任何变化。
假设有一个Map<String,Object>方法; 如果map 没有关联的key,就会返回null。
1 | Object value = map.get("key"); |
可以替换成
1 | Optional<Object> value = Optional.ofNullable(map.get("key")); |
索引,用于提升数据库的查找速度。
索引主要是基于Hash表和B+树。
加速查找速度的数据结构,常见的有两类:
(1)哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1);
(2)树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O(lg(n));
如果是单行查询确实是哈希索引更快。对于group by 、order by 、比较<>哈希索引时间复杂度会退化成O(n),而树的有序性,依旧能保持O(logn)的高效率。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。 磁盘里的数据加载到内存的时候,是以页为单位加载的,节点与节点之间的数据是不联系的,所以不同的节点,很可能分布在不同磁盘页中,
磁盘的加载次数和树的高度是关联的。越矮加载次数越少。